Cours 1: Jeu d'instruction.
Quelles instructions un jeu d'instruction de processeur généraliste doit-il
offrir? Quelle doit être la représentation matérielle de ces instructions?
Voici le jeu d'instruction MIPS représentatif des architectures
chargement/rangement.
Les instructions se déclinent en trois formats décrits dans la figure ci-dessous.

Les instructions de type R sont des instructions à deux sources et une
destination en registres. Ce sont les instructions de calculs entiers
et flottants. Parmi ces calculs, on trouve les comparaisons de registres,
dont le résultat booléen est écrit dans le registre de destination.
Les instructions de type I ont une source en registre et une autre
(la source droite) qui est une constante 16-bits signée. Ce sont
les calculs entiers avec constante (par exemple i++), les chargements
(les sources additionnées forment l'adresse virtuelle d'accès) et les
rangements (le champ servant au registre de destination sert dans ce cas
à désigner le registre à ranger en mémoire). Il y a aussi les sauts
conditionnels (la constante est le déplacement signé du saut, relatif à PC,
le champ de destination n'est pas utilisé), les initialisations
de registres (la constante est placée en moitié haute ou basse) et enfin
les sauts indirects (la constante et le champ de destination ne sont pas
utilisés, l'adresse de retour des sauts avec lien est rangée dans R31).
Les instructions du type J n'ont pas de destination explicite. Elles
ont une source constante de 26-bits signée. Ce sont les instructions de
sauts inconditionnels immédiats. La source représente le déplacement signé
du saut, relatif à PC. Les sauts avec lien rangent leur adresse de retour
dans R31.
L'architecture MIPS définit 32 registres entiers (le registre R0 est la
constante 0, le registre R31 contient l'adresse de retour) et 32 registres
flottants simple précision, que l'on peut combiner par paire de registres
adjacents pour former 16 registres double précision.
La liste exhaustive des instructions MIPS et leur codage peut être
consultée ici .
A titre d'exemple, voici un programme C.
#include <stdio.h>
int main (int argc, char *argv[]) {
int i;
int somme = 0;
for (i=0; i<=100; i++) somme += (i*i);
printf("la somme des carrés des 100 premiers entiers est %d\n", somme);
}
Voici sa traduction en assembleur MIPS.
.text
.align 2 // alignment 2^2 bytes
.globl main
main:
subu $sp, $sp, 32 // R29 (stack pointer); allocate the frame
sw $ra, 20($sp) // R31; push the return address
sw $0, 24($sp) // R0 (constant 0); somme = 0;
sw $0, 28($sp) // i = 0;
loop:
lw $t6, 28($sp) // R14 (temporary 6; not pushed); i
mul $t7, $t6, $t6 // R15 (temporary 7; not pushed); i*i
lw $t8, 24($sp) // R24 (temporary 8; not pushed); somme
addu $t9, $t8, $t7 // R25 (temporary 9; not pushed); somme + i*i
sw $t9, 24($sp) // somme += (i*i);
addu $t0, $t6, 1 // R8 (temporary 0; not pushed); i+1
sw $t0, 28($sp) // i++;
ble $t0, 100, loop // if (i<=100) goto loop;
la $a0, str // R4 (argument 0); "la somme ..."
lw $a1, 24($sp) // R5 (argument 1); somme
jal printf // printf("la somme ...", somme);
move $v0, $0 // R2 = 0 (result value 0 is 0)
lw $ra, 20($sp) // pop return address
addu $sp, $sp, 32 // free function stack frame
jr $ra // return
.data
.align 0 // alignment disabled
str:
.asciiz "la somme des carrés des 100 premiers entiers est %d\n"
Voici une version légèrement différente (la borne de la boucle est une variable).
/*
#include <stdio.h>
int main (int argc, char *argv[]) {
int i, n;
int somme = 0;
printf("n: ");
scanf("%d", &n);
for (i=0; i<n; i++) somme += (i*i);
printf("la somme des carrés des %d premiers entiers est %d\n", n, somme);
}
*/
.text
.align 2
.globl main
main:
subu $sp, $sp, 32
sw $ra, 16($sp)
sw $0, 24($sp) // somme = 0;
sw $0, 28($sp) // i = 0;
la $a0, str1 // "n: "
jal printf // printf("n: ");
la $a0, str2
la $a1, 20($sp) // &n
jal scanf // scanf("%d", &n);
lw $t5, 20($sp) // n
beq $t5, $0, e0 // if (n==0) goto e0;
loop:
lw $t6, 28($sp) // i
mul $t7, $t6, $t6 // i*i
lw $t8, 24($sp) // somme
addu $t9, $t8, $t7 // somme + i*i
sw $t9, 24($sp) // somme += (i*i);
addu $t0, $t6, 1 // i+1
sw $t0, 28($sp) // i++;
ble $t0, $t5, loop // if (i<=n) goto loop;
e0:
la $a0, str3 // "la somme ..."
lw $a1, 20($sp) // n
lw $a2, 24($sp) // somme
jal printf // printf("la somme ...", n, somme);
move $v0, $0
lw $ra, 16($sp)
addu $sp, $sp, 32
jr $ra
.data
.align 0
str1:
.asciiz "n: "
str2:
.asciiz "%d"
str3:
.asciiz "la somme des carrés des 100 premiers entiers est %d\n"
Voici deux traductions différentes d'un même code. La première emploie un
saut conditionnel (ce qui n'est pas bon pour l'ILP) et la seconde emploie
une instruction de move conditionnel, apparue dans les versions
récentes du jeu d'instructions MIPS (remarque: les données étant unsigned , on effectue une comparaison non signée ( bgeu )).
/*
unsigned int z;
main() {
unsigned int x, y;
scanf("%d", &x);
scanf("%d", &y);
if (x<y)
z = x;
else
z = y;
printf("%d\n", z);
}
*/
// première version: saut conditionnel
.text
.align 2
.globl main
main:
subu $sp, $sp, 32
sw $ra, 20($sp)
la $a0, str1
la $a1, 24($sp) // &x
jal scanf // scanf("%d", &x);
la $a0, str1
la $a1, 28($sp) // &y
jal scanf // scanf("%d", &y);
lw $t6, 24($sp) // x
lw $t7, 28($sp) // y
bgeu $t6, $t7, e0 // if (x>=y) goto e0;
sw $t6, z // z = x;
b e1 // goto e1;
e0:
sw $t7, z // z = y;
e1:
la $a0, str2
lw $a1, z
jal printf // printf("%d\n", z);
move $v0, $0
lw $ra, 20($sp)
addu $sp, $sp, 32
jr $ra
.data
.align 0
str1:
.asciiz "%d"
str2:
.asciiz "%d\n"
.align 2
z:
.space 4 // reserve 4 bytes for z
// deuxième version: move conditionnel
.text
.align 2
.globl main
main:
subu $sp, $sp, 32
sw $ra, 20($sp)
la $a0, str1
la $a1, 24($sp) // &x
jal scanf // scanf("%d\n", &x);
la $a0, str1
la $a1, 28($sp) // &y
jal scanf // scanf("%d\n", &y);
lw $t6, 24($sp) // x
lw $t7, 28($sp) // y
sltu $t8, $t6, $t7 // t8 = (x<y)
movn $t9, $t6, $t8 // if (t8!=0) t9 = x
movz $t9, $t7, $t8 // if (t8==0) t9 = y
sw $t9, z // z = (x<y)?x:y;
la $a0, str2
lw $a1, z
jal printf // printf("%d\n", z);
move $v0, $0
lw $ra, 20($sp)
addu $sp, $sp, 32
jr $ra
.data
.align 0
str1:
.asciiz "%d"
str2:
.asciiz "%d\n"
.align 2
z:
.space 4
Voici un calcul de racine carrée qui implémente un while .
/*
#include <stdio.h>
int main (int argc, char *argv[]) {
unsigned int c = 0, i = 1, n;
printf("n: ");
scanf("%d", &n);
while (c<n) {
c += i;
i += 2;
}
printf("la racine carrée de %d est %d\n", n, i-1);
}
*/
.text
.align 2
.globl main
main:
subu $sp, $sp, 32
sw $ra, 16($sp)
sw $0, 24($sp) // c = 0;
li $t0, 1
sw $t0, 28($sp) // i = 1;
la $a0, str1
jal printf // printf("n: ");
la $a0, str2
la $a1, 20($sp) // &n
jal scanf // scanf("%d", &n);
lw $t5, 20($sp) // n
beq $t5, $0, e0 // if (n==0) goto e0;
loop:
lw $t6, 28($sp) // i
lw $t7, 24($sp) // c
addu $t7, $t7, $t6 // c+i
sw $t7, 24($sp) // c += i;
addu $t6, $t6, 2 // i+2
sw $t6, 28($sp) // i += 2;
bltu $t7, $t5, loop // if (c<n) goto loop;
e0:
la $a0, str3 // "la racine ..."
lw $a1, 20($sp) // n
lw $a2, 24($sp) // i
subu $a2, $a2, 1 // i-1
jal printf // printf("la racine ...", n, i-1);
move $v0, $0
lw $ra, 16($sp)
addu $sp, $sp, 32
jr $ra
.data
.align 0
str1:
.asciiz "n: "
str2:
.asciiz "%d"
str3:
.asciiz "la racine carrée de %d est %d\n"
Voici un exemple de fonction récursive avec un paramètre fonction engendrant
une instruction d'appel indirect jalr .
/*
#include <stdio.h>
ecrire(unsigned int n, unsigned int d, unsigned int a) {
printf("le disque %d va du piquet %d au piquet %d\n", n, d, a);
}
hanoi(unsigned int n, unsigned int d, unsigned int a, unsigned int i, int (*f)()) {
if (n==0) return;
hanoi(n-1, d, i, a, f);
f(n, d, a);
hanoi(n-1, i, a, d, f);
}
int main (int argc, char *argv[]) {
unsigned int n;
printf("n: ");
scanf("%d", &n);
hanoi(n, 1, 3, 2, ecrire);
}
*/
.text
.align 2
.globl main
main:
subu $sp, $sp, 32
sw $ra, 24($sp)
la $a0, str1
jal printf // printf("n: ");
la $a0, str2
la $a1, 28($sp) // &n
jal scanf // scanf("%d", &n);
lw $a0, 28($sp) // n
li $a1, 1 // 1
li $a2, 3 // 3
li $a3, 2 // 2
li $a4, ecrire // ecrire
jal hanoi // hanoi(n, 1, 3, 2, ecrire);
move $v0, $0
lw $ra, 24($sp)
addu $sp, $sp, 32
jr $ra
ecrire:
la $a0, str3 // "le disque ..."
move $a3, $a2 // a
move $a2, $a1 // d
move $a1, $a0 // n
jal printf // printf("le disque ...", n, d, a);
jr $ra
hanoi:
beqz $a0, e0 // if (n==0) goto e0;
subu $sp, $sp, 32
sw $ra, 24($sp)
addiu $a0, $a0, -1 // n-1
move $t0, $a2
move $a2, $a3 // i
move $a3, $t0 // a
jal hanoi // hanoi(n-1, d, i, a, ecrire);
move $t0, $a2
move $a2, $a3 // a
move $a3, $t0 // i
addiu $a0, $a0, 1 // n
jalr $a5 // ecrire(n, d, a);
addiu $a0, $a0, -1 // n-1
move $t0, $a1
move $a1, $a3 // i
move $a3, $t0 // d
jal hanoi // hanoi(n-1, i, a, d, ecrire);
lw $ra, 24($sp)
addu $sp, $sp, 32
e0:
jr $ra
.data
.align 0
str1:
.asciiz "n: "
str2:
.asciiz "%d"
str3:
.asciiz "le disque %d va du piquet %d au piquet %d\n"
Voici un tableau qui montre quelles sont les fréquences d'utilisation des
instructions MIPS dans les programmes de la suite de benchmarks SPEC2000.
Fréquence d'utilisation des instructions MIPS dans SPEC2000
| |
Fréquence dans SPECint |
Fréquence dans SPECfp |
| instr |
gap |
gcc |
gzip |
mcf |
perl |
moyen |
applu |
art |
equak |
lucas |
swim |
moyen |
| load |
26,5% |
25,1% |
20,1% |
30,3% |
28,7% |
26,0% |
13,8% |
18,1% |
22,3% |
10,6% |
9,1% |
15,0% |
| store |
10,3% |
13,2% |
5,1% |
4,3% |
16,2% |
10,0% |
2,9% |
0,0% |
0,8% |
3,4% |
1,3% |
2,0% |
| add |
21,1% |
19,0% |
26,9% |
10,1% |
16,7% |
19,0% |
30,4% |
30,1% |
17,4% |
11,1% |
24,4% |
23,0% |
| sub |
1,7% |
2,2% |
5,1% |
3,7% |
2,5% |
3,0% |
2,5% |
0,0% |
0,1% |
2,1% |
3,8% |
2,0% |
| mul |
1,4% |
0,1% |
0,0% |
0,0% |
0,0% |
0,0% |
2,3% |
0,0% |
0,0% |
1,2% |
0,0% |
1,0% |
| comp |
2,8% |
6,1% |
6,6% |
6,3% |
3,8% |
5,0% |
0,0% |
7,4% |
2,1% |
0,0% |
0,0% |
2,0% |
| init |
4,8% |
2,5% |
1,5% |
0,1% |
1,7% |
2,0% |
13,7% |
0,0% |
1,0% |
1,8% |
9,4% |
5,0% |
| bcond |
9,3% |
12,1% |
11,0% |
17,5% |
10,9% |
12,0% |
2,5% |
11,5% |
2,9% |
0,6% |
1,3% |
4,0% |
| cmov |
0,4% |
0,6% |
1,1% |
0,1% |
1,9% |
1,0% |
0,0% |
0,3% |
0,1% |
0,0% |
0,0% |
0,0% |
| jump |
0,8% |
0,7% |
0,8% |
0,7% |
1,7% |
1,0% |
0,0% |
0,0% |
0,1% |
0,0% |
0,0% |
0,0% |
| call |
1,6% |
0,6% |
0,4% |
3,2% |
1,1% |
1,0% |
0,0% |
0,0% |
0,7% |
0,0% |
0,0% |
0,0% |
| ret |
1,6% |
0,6% |
0,4% |
3,2% |
1,1% |
1,0% |
0,0% |
0,0% |
0,7% |
0,0% |
0,0% |
0,0% |
| shift |
3,8% |
1,1% |
2,1% |
1,1% |
0,5% |
2,0% |
0,7% |
0,0% |
0,2% |
1,9% |
0,0% |
1,0% |
| and |
4,3% |
4,6% |
9,4% |
0,2% |
1,2% |
4,0% |
0,0% |
0,0% |
0,2% |
1,8% |
0,0% |
0,0% |
| or |
7,9% |
8,5% |
4,8% |
17,6% |
8,7% |
9,0% |
0,8% |
1,1% |
2,3% |
1,0% |
7,2% |
2,0% |
| xor |
1,8% |
2,1% |
4,4% |
1,5% |
2,8% |
3,0% |
0,0% |
3,2% |
0,1% |
0,0% |
0,0% |
1,0% |
| logiq |
0,1% |
0,4% |
0,1% |
0,1% |
0,3% |
0,0% |
0,0% |
0,0% |
0,1% |
0,0% |
0,0% |
0,0% |
| fload |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
11,4% |
12,0% |
19,7% |
16,2% |
16,8% |
15,0% |
| fstor |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
4,2% |
4,5% |
2,7% |
18,2% |
5,0% |
7,0% |
| fadd |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
2,3% |
4,5% |
9,8% |
8,2% |
9,0% |
7,0% |
| fsub |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
2,9% |
0,0% |
1,3% |
7,6% |
4,7% |
3,0% |
| fmul |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
8,6% |
4,1% |
12,9% |
9,4% |
6,9% |
8,0% |
| fdiv |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,3% |
0,6% |
0,5% |
0,0% |
0,3% |
0,0% |
| fmov |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,7% |
0,9% |
1,2% |
1,8% |
0,9% |
1,0% |
| fcomp |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,9% |
0,6% |
0,8% |
0,0% |
0,0% |
| fcmov |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,6% |
0,0% |
0,8% |
0,0% |
0,0% |
| fautre |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
0,0% |
1,6% |
0,0% |
0,0% |
Voici une synthèse de ces résultats.
La première colonne min représente le plus petit taux parmi ceux des 5 benchmarks
de SPECint.
La
seconde colonne min est le plus petit taux parmi ceux des 5 benchmarks
de SPECfp et la troisième colonne min est le plus petit taux parmi les 10 de
SPEC2000.
La première colonne max est le plus grand des 5 de SPECint.
La seconde colonne max est le plus grand des 5 taux de SPECfp.
La troisième colonne max est le plus grand des 10 taux de SPEC2000.
Enfin, les trois colonnes moy sont les taux moyens pour SPECint, SPECfp et SPEC2000.
Fréquence d'utilisation des instructions MIPS dans SPEC2000
| |
Fréquence dans SPECint |
Fréquence dans SPECfp |
Fréquence dans SPEC2000 |
| catégorie |
min |
max |
moy |
min |
max |
moy |
min |
max |
moy |
| accès mém |
25,2% |
44,9% |
36,0% |
32,2% |
48,4% |
39,0% |
25,2% |
48,4% |
37,5% |
| add/sous |
20,1% |
38,6% |
27,0% |
13,2% |
37,5% |
27,0% |
13,2% |
38,6% |
27,0% |
| move |
0,2% |
5,2% |
3,0% |
0,3% |
13,7% |
5,0% |
0,2% |
13,7% |
4,0% |
| op logiq |
13,0% |
19,4% |
16,0% |
0,8% |
7,2% |
3,0% |
0,8% |
19,4% |
9,5% |
| sauts cond |
9,3% |
17,5% |
12,0% |
0,6% |
11,5% |
4,0% |
0,6% |
17,5% |
8,0% |
| sauts incond |
1,6% |
7,1% |
3,0% |
0,0% |
1,5% |
0,0% |
0,0% |
7,1% |
1,5% |
| décalages |
0,5% |
3,8% |
2,0% |
0,0% |
1,9% |
1,0% |
0,0% |
3,8% |
1,5% |
| mult int |
0,0% |
1,4% |
0,0% |
0,0% |
2,3% |
1,0% |
0,0% |
2,3% |
0,5% |
| fadd/sous |
0,0% |
0,0% |
0,0% |
5,2% |
16,6% |
10,0% |
0,0% |
16,6% |
5,0% |
| fmul |
0,0% |
0,0% |
0,0% |
4,1% |
12,9% |
8,0% |
0,0% |
12,9% |
4,0% |
| fdiv |
0,0% |
0,0% |
0,0% |
0,0% |
0,6% |
0,0% |
0,0% |
0,6% |
0,0% |
| fmove |
0,0% |
0,0% |
0,0% |
0,7% |
2,6% |
1,0% |
0,0% |
2,6% |
0,5% |
Il faut remarquer que plus d'une instruction sur 3 est un accès à la mémoire (et jusqu'à une
instruction sur 2). Cela tient
au fait que MIPS est une architecture chargement/rangement .
Par ailleurs, une instruction sur 12 est un saut conditionnel (cela peut aller jusqu'à une
instruction sur 6).
Il y a peu de sauts inconditionnels. Ce sont surtout des appels (saut immédiat avec lien) et retours
(saut indirect).
Pour les calculs et les unités nécessaires, une instruction sur 4 utilise l'additionneur
entier (cela peut aller jusqu'à une sur 3).
Une instruction sur 10 est une opération logique (avec un pic à une instruction sur 5).
Les décalages sont peu nombreux, de même que les multiplications entières. Il n'y a pas de division entière et un tel opérateur est superflu (il est préférable d'émuler l'opération).
Dans les codes flottants, une instruction sur 10 utilise l'additionneur flottant avec un pic
à une instruction sur 6.
Une instruction sur 12 est
une multiplication flottante avec un maximum de une sur 8.
Les
divisions flottantes sont très minoritaires mais un opérateur est utile pour certains codes.
La figure ci-dessous représente l'oganisation générale d'un processeur.
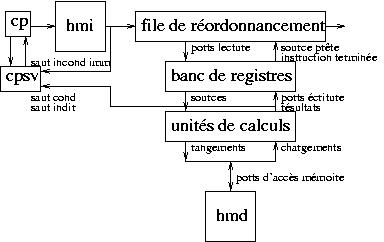
Le compteur de programme cp pointe sur la hiérarchie mémoire
d'instructions hmi .
A chaque cycle, on extrait d instructions ( d est le degré superscalaire du processeur) d'un même bloc de base (sans saut)
ou de plusieurs blocs de base successifs.
Les instructions extraites sont mises en file d'attente pour leur exécution.
Au passage, elles sont organisées en ordre partiel de leurs dépendances
LAE (Lecture Après Ecriture).
A partir du compteur de programme, on calcule ou on prédit à chaque cycle le compteur
de programme suivant cpsv .
Une fois les instructions lues de la mémoire, un examen permet d'en repérer
les sauts inconditionnels immédiats, ce qui implique un éventuel ajustement
du compteur de programme s'il a été incorrectement prédit.
A chaque cycle, parmi les instructions dont les sources sont disponibles (les instructions
prêtes ), on en lance au plus une par unité de calcul (par exemple,
une opération pour l'UAL, une addition flottante, un saut conditionnel
et un chargement).
Chaque unité de calcul dispose de ses ports de lecture et d'écriture dans le banc de registres.
Les opérateurs des unités de calcul sont pipelinés, ce qui permet de lancer une
nouvelle opération à chaque cycle. Le diviseur n'est pas pipeliné, ce qui impose
une latence d'un cycle par paire de bits de la mantisse à produire. La
hiérarchie mémoire de donnée est pipelinée: l'accès au cache est non bloquant.
Le résultat est écrit dans le banc de registres, les sources dépendantes
deviennent disponibles et l'instruction ayant calculé le résultat est
terminée.
La direction des sauts conditionnels et la cible des sauts indirects sont
confrontées aux prédictions. En cas de différence, un nouveau cpsv
est envoyé à l'unité d'extraction et la file de réordonnancement est vidée.
Une fois terminées, les instructions sortent de la file de réordonnancement dans
l'ordre de leur extraction. Les ordres d'écriture en mémoire sont effectués.